K-Nearest Neighbors (KNN) in Python
Clear, original guide to KNN in Python: intuition, distance metrics, scikit-learn code (KNeighborsClassifier), choosing k, scaling, limitations, and practical tips.
Drake Nguyen
Founder · System Architect
KNN in Python: an approachable guide to the k-nearest neighbors algorithm
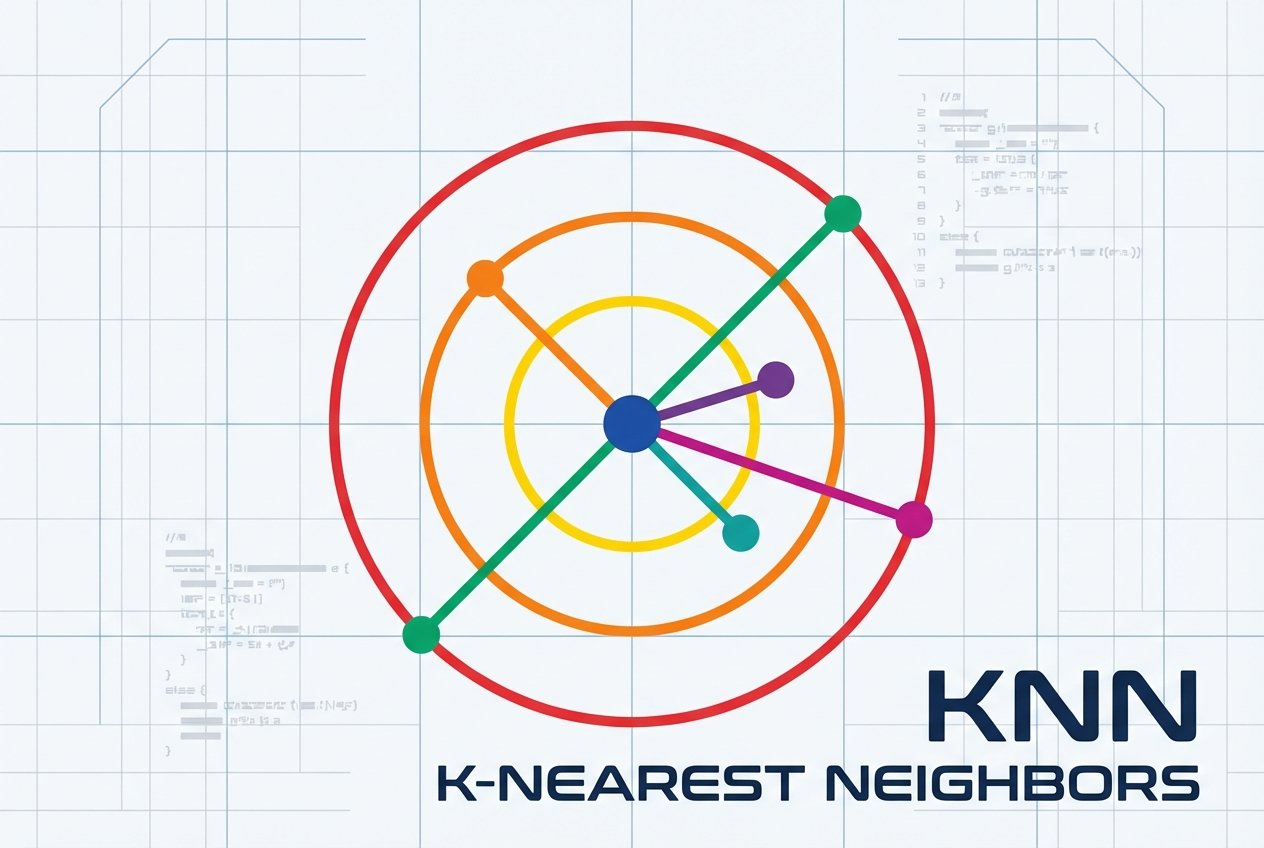
K-nearest neighbors (kNN) is a simple, instance-based supervised learning algorithm used for both classification and regression tasks. When working with machine learning in Python, kNN is easy to prototype with scikit-learn and is valuable for understanding concepts like distance metrics, feature scaling, and lazy learning.
The intuition behind the k-nearest neighbors algorithm
The core idea of the k nearest neighbors algorithm is intuitive: a data point is likely to share the label or value of nearby points. In classification, a KNN classifier assigns the most common class among the k nearest neighbors. In regression, the algorithm predicts the average (or a distance-weighted average) of neighbors' target values.
Analogy
Think of social influence: if you spend most time with one person, you may adopt that person’s preferences (k=1). If you regularly interact with five friends, your preferences more closely resemble the group average (k=5). This mirrors how the k value in KNN controls local vs. broader influence.
Distance metrics in KNN
How “near” is measured matters. Common distance metrics in KNN include:
- Euclidean distance (Minkowski with p=2) — common for continuous features.
- Manhattan distance (Minkowski with p=1) — robust when axes are independent.
- Minkowski distance — general form that covers Euclidean and Manhattan.
Scaling features (for example with StandardScaler) is essential because Euclidean distance is sensitive to feature magnitudes. Without scaling, large-valued features can dominate neighbor selection.
Implementing KNN in Python (scikit-learn example)
This example shows a typical workflow: create data, split it, scale features, fit a KNeighborsClassifier, and evaluate. The example uses scikit learn KNN utilities and demonstrates a knn classifier in python scikit learn.
1) Imports
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
2) Create a synthetic dataset
# k nearest neighbors algorithm in python example
X, y = make_blobs(n_samples=500, n_features=2, centers=4, cluster_std=1.5, random_state=4)
3) Train / test split and scaling
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
4) Fit KNN classifiers and predict
# KNeighborsClassifier example python
knn5 = KNeighborsClassifier(n_neighbors=5, metric='minkowski', p=2)
knn1 = KNeighborsClassifier(n_neighbors=1)
knn5.fit(X_train_scaled, y_train)
knn1.fit(X_train_scaled, y_train)
y_pred_5 = knn5.predict(X_test_scaled)
y_pred_1 = knn1.predict(X_test_scaled)
print('Accuracy with k=5:', accuracy_score(y_test, y_pred_5) * 100)
print('Accuracy with k=1:', accuracy_score(y_test, y_pred_1) * 100)
How to choose k (best k value for KNN)
Choosing the k value in KNN balances bias and variance. Practical tips:
- Small k (e.g., k=1) can overfit and be sensitive to noise.
- Large k can underfit by oversmoothing class boundaries.
- Use odd k for binary classification to reduce ties.
- Try sqrt(n_samples) as a heuristic starting point.
- Use cross-validation or an elbow plot of validation accuracy vs. k to find the best k.
KNN regression and variants
For continuous targets, KNN regression predicts the mean or a weighted mean of neighbors. scikit-learn provides KNeighborsRegressor for these tasks. You can also weight neighbors by distance to give closer points more influence.
Limitations of KNN
- Storage and prediction cost: KNN stores the full training set and can be slow for large datasets.
- Curse of dimensionality: performance degrades with many irrelevant features—perform feature selection or dimensionality reduction first.
- Feature scaling required: distance metrics can be dominated by unscaled features.
- Cannot extrapolate beyond observed data—limited for novel rare events.
Practical recommendations
- Always scale numeric features (StandardScaler or MinMaxScaler).
- Experiment with distance metrics (Euclidean, Manhattan, Minkowski) for your data.
- Use cross-validation for hyperparameter tuning: k value, weights, and metric.
- For large datasets, consider approximate nearest neighbors libraries or different supervised learning algorithms.
Conclusion
KNN in Python is an accessible supervised learning algorithm that helps illustrate instance-based and lazy learning concepts. With scikit-learn's KNeighborsClassifier and KNeighborsRegressor you can quickly prototype classification and regression solutions, but remember to scale features and tune the k value and distance metrics for best results.
For hands-on practice try: knn algorithm python from scratch to learn the mechanics, then move to scikit-learn for production-ready workflows.