Syntax Parsing Guide: Comparing Top-Down and Bottom-Up Techniques
Master syntax parsing with this guide on top-down and bottom-up techniques. Compare LL vs LR, recursive descent, and LALR performance for modern compiler design.
Drake Nguyen
Founder · System Architect
Introduction to Syntax Parsing in Compiler Design
Building a robust programming language or a custom compiler requires mastering syntax parsing. Often positioned as the crucial second phase of the compilation process—immediately following lexical analysis—this step ensures that a stream of tokens conforms to the strict structural rules of the language. Any comprehensive compiler design tutorial will emphasize that syntax parsing acts as the bridge between raw source code text and the deep structural understanding a compiler needs to generate executable machine code.
At its core, a compiler parser takes the linear sequence of tokens produced by the lexer and organizes them into a hierarchical, mathematical structure. By evaluating top-down vs bottom-up parsing techniques for modern development, systems programmers can build more efficient, memory-safe, and highly optimized compilers. In this guide, we will unpack fundamental parsing algorithms, explore the distinct advantages of both methodologies, and help you determine which architecture best suits your development constraints.
Core Concepts: Context-Free Grammar and Syntax Tree Generation
Before diving into specific parsing implementations, it is essential to understand the frameworks that make syntax analysis possible. The foundation of any compiler parser is a Context-Free Grammar (CFG). A CFG defines the set of rules—known as productions—that govern how language tokens can be legally combined.
The primary goal of this phase is accurate syntax tree generation, often resulting in a derivation tree or an Abstract Syntax Tree (AST). This tree maps the syntactical structure of the source code. However, for seamless syntax tree generation to occur, developers must focus heavily on ambiguous grammar removal. If a grammar allows a single string of tokens to produce more than one valid derivation tree, the parser cannot definitively understand the programmer's intent. Ambiguous grammar removal forces the language grammar into a deterministic state, ensuring that parsing algorithms behave consistently.
- Context-Free Grammar: The formal mathematical rulebook for allowable token combinations.
- Derivation Tree: The hierarchical representation of the code's grammatical and logical structure.
- Ambiguous Grammar Removal: The necessary process of rewriting production rules to eliminate structural double-meanings.
Top-Down Syntax Parsing Techniques Explained
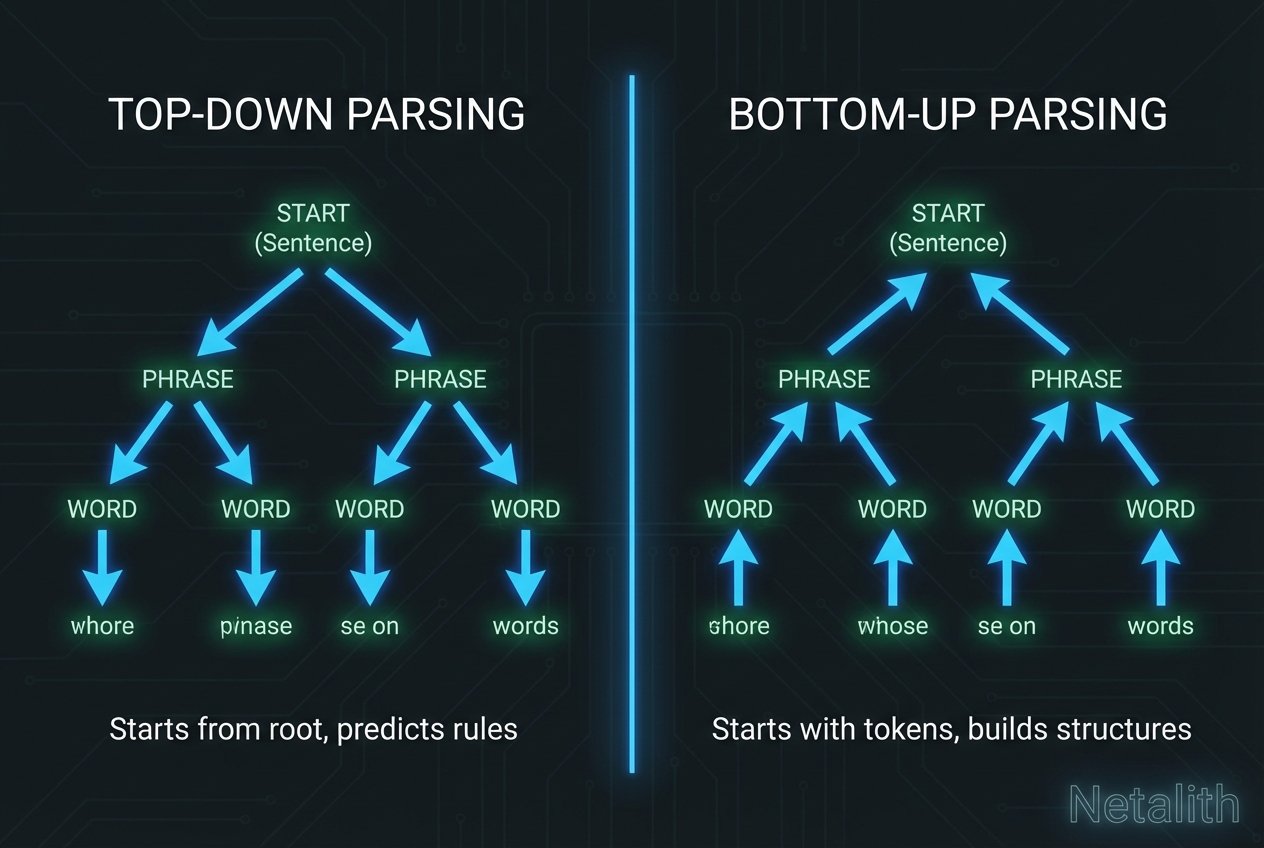
Top-down parsing algorithms attempt to reconstruct the derivation tree from the root node down to the leaf nodes. As systems engineers evaluate top-down vs bottom-up parsing techniques in current compiler design, top-down approaches remain highly favored for their straightforward implementation and ease of debugging. These parsers read the input from left to right and attempt to match the incoming token stream against the grammar productions.
Predictive Parsing Table and Lookahead Tokens
To avoid the steep performance costs of backtracking—guessing a rule and then undoing it if it fails—modern top-down systems rely on predictive parsing. A predictive parsing table acts as a deterministic routing matrix, telling the parser exactly which production rule to apply based on the current non-terminal and the upcoming lookahead tokens. By pre-analyzing lookahead tokens, the parser can safely commit to a derivation path without needing to reverse its structural decisions later.
When to Use Recursive Descent Parsing
One of the most widely implemented top-down approaches is the recursive descent parser. But exactly when to use recursive descent parsing? This method is ideal when you are building a hand-written compiler parser for a language with a relatively simple or continuously evolving grammar. Because a recursive descent parser assigns a distinct recursive function to each non-terminal in the grammar, the resulting code is highly readable and mirrors the CFG itself.
However, it requires the grammar to be free of left-recursion. When paired with well-calculated lookahead tokens and a robust predictive parsing table, recursive descent parsing provides an elegant, highly maintainable solution for complex syntax analysis tasks.
Bottom-Up Parsing and Shift-Reduce Mechanisms
If top-down parsing builds the syntax tree from the root to the leaves, bottom-up parsing does the exact opposite. It starts with the raw input string and reduces it upwards until it successfully reaches the start symbol. In the realm of syntax analysis, bottom-up methods are celebrated for their power, able to handle a much larger, more complex class of grammars than their top-down equivalents.
Shift-Reduce Parsing and Handle Pruning
The operational heart of bottom-up syntax analysis is shift-reduce parsing. The parser utilizes a stack and an input buffer. It "shifts" incoming tokens onto the stack one by one. Once the symbols at the top of the stack match the right side of a specific production rule (a sequence known as a "handle"), the parser "reduces" them by replacing the handle with the corresponding non-terminal on the left side of the rule.
This critical reduction step is known as handle pruning in compilers. Through successive shift and reduce operations—guided by state transitions heavily modeled on finite automata—the parser effectively collapses the entire token stream into a single root symbol.
LALR vs Canonical LR Parser Performance
When selecting a bottom-up tool like YACC or GNU Bison, developers must carefully weigh lalr vs canonical lr parser performance. Both are members of the LR parsing family (Left-to-right, Rightmost derivation), but they differ drastically in memory footprint and grammatical flexibility:
- Canonical LR (LR(1)): The most powerful variant, capable of pinpointing errors immediately. However, its state machine is massive, leading to high memory consumption, which can negatively impact the overall efficiency of parsing algorithms.
- LALR (Lookahead LR): LALR merges states from the Canonical LR parser that have identical core items but different lookaheads. This drastically reduces the number of parser states.
For most production-grade compilers, the lalr vs canonical lr parser performance debate strongly favors LALR. The reduced state count significantly speeds up the syntax parsing phase, leaving more system resources available for subsequent stages like intermediate representation generation, symbol table construction, and semantic analysis.
Conclusion: Choosing the Right Approach for Syntax Parsing
Understanding the ll vs lr parsing algorithms compared in this guide is critical for effective language development. Once the syntax parsing phase successfully maps out the structural integrity of the code, the compiler confidently moves into deeper phases like code optimization and semantic analysis.
LL (Top-Down) parsers are simpler to write by hand and offer excellent error reporting, but they are restricted to grammars without left-recursion. Conversely, LR (Bottom-Up) parsers are much more powerful and handle a broader range of grammars, though they are tedious to write manually and typically require parser generators. By choosing the right technique for your syntax parsing needs, you ensure your compiler is both efficient and maintainable for long-term project success.